
금융의 세계는 너무 만연하고 일반적으로 만연한 질병에 시달리고 있어 "전문가"라도 이를 심각하게 받아들이지 않는 것 같습니다. 금세 금단의 기미가 보이지 않는 질병을 '데이터 마이닝'이라고 합니다. 이것이 인덱스 구성에 어떤 영향을 미치며 왜 주의해야 하는지입니다. 이것은 개인적인 이유로 익명을 원하는 금융 시장 전문가의 게스트 게시물입니다.
'기술' 배경에서 온 많은 독자들은 항상 데이터 마이닝에 대해 긍정적인 의견을 가지고 있으며, 이는 여러 분야에서 데이터 및 데이터 마이닝이 놀라운 효과를 거두었기 때문입니다. 예측하기 - 데이터 및 데이터 마이닝은 매우 유용했습니다. 그러나 재무 및 투자 관리의 맥락에서 '데이터 마이닝'은 골칫거리입니다.
재무/투자 관리의 맥락에서 데이터 마이닝이 무엇인지 정의하겠습니다. 데이터 마이닝은 경제적이고 직관적인 근거 없이 과거의 데이터를 살펴보는 것 외에는 패턴을 찾는 것, 특히 '우수한' 성과를 내는 것입니다. 컴퓨팅 성능의 성장과 일중 데이터의 대규모 가용성을 감안할 때 반쯤 괜찮은 프로그래머가 몇 가지 뛰어난 결과를 도출하기 위해 수백만 건은 아니더라도 수천 건의 백테스트를 수행하는 간단한 스크립트를 작성하는 것은 그리 어렵지 않습니다. 그러나 전문가와 투자자 모두 단일 주식이나 뮤추얼 펀드 단위를 구매한 적이 있는 모든 사람이 이 말을 버렸음에도 불구하고 "과거는 미래를 나타내지 않는다"는 투자의 가장 핵심적인 신조를 편리하게 잊어버립니다.
다음은 작동 중인 데이터 마이닝의 예입니다. 세계 최대의 지수 제공업체인 MSCI는 지수를 추적하거나 지수에 대해 벤치마킹되는 수조 달러를 보유한 MSCI 가치 지수, MSCI 가치 가중 지수, MSCI '향상된' 가치 지수의 세 가지 '가치' 지수를 보유하고 있습니다. 논리적인 사람이라면 누구나 다음과 같은 질문을 할 것입니다. 동일한 공급자가 제공하는 세 가지 다른 가치 지수가 있는 이유는 무엇입니까? 어느 것에 투자해야 할까요? 이들의 차이점은 무엇인가요? 어떻게 하나가 다른 것보다 낫습니까? MSCI Value 제품군 중 가장 오래된 구성원은 1997년부터 운영되고 있으며 가치 가중 지수는 2010년 12월에 출시되었으며 Enhanced Value는 2015년 4월에 출시되었습니다. 물론 새로 출시된 지수는 백테스트에서 이전 지수보다 우수한 성과를 거두었습니다. ".
다음 그림은 광범위한 시장 지수에 대한 세 가지 가치 지수 모두의 NAV 비율을 보여줍니다. NAV 비율은 모르는 사람들을 위해 한 지수 NAV를 다른 지수 NAV로 나눈 비율입니다. 비율에 대한 경제적 해석은 분자 지수/포트폴리오에서 '롱', 분모 지수/포트폴리오에서 '숏'으로 가는 롱숏 포트폴리오의 성과입니다. 따라서 NAV 비율이 올라가면 분자 지수가 분모 지수(이 경우 벤치마크)를 능가하고 하락하면 분자 지수가 분모를 하회합니다. 보시다시피 최신 지수는 특히 백테스트에서 이전 지수를 훨씬 능가합니다. 또한, 이전 지수의 장기간 나쁜 성과에 이어 새로운 지수가 출시되는 것도 흥미롭습니다. 2+3=5를 구성하는 데에는 법의학 분석가와 조사 기자로 구성된 팀이 필요하지 않습니다. 인덱스가 시작되고 라이브 상태가 되면 어떻게 되었습니까? 데이터 마이닝의 결과입니다. 데이터 마이닝으로 인해 어려움을 겪는 비 강건한 백테스트는 조만간 실제 색상을 드러낼 것입니다. 사실은 학문적 가치 요소가 10년 이상 실적이 저조했다는 것입니다. 데이터 마이닝의 양은 그 사실을 바꿀 수 없습니다. 우리가 가치를 어떻게 보든, 그것을 피할 수는 없습니다. 그러나 환상적인 과거 실적이 판매됩니다. 남자는 먹어야 하고, 먹으려면 팔아야 하니까..!
<노스크립트>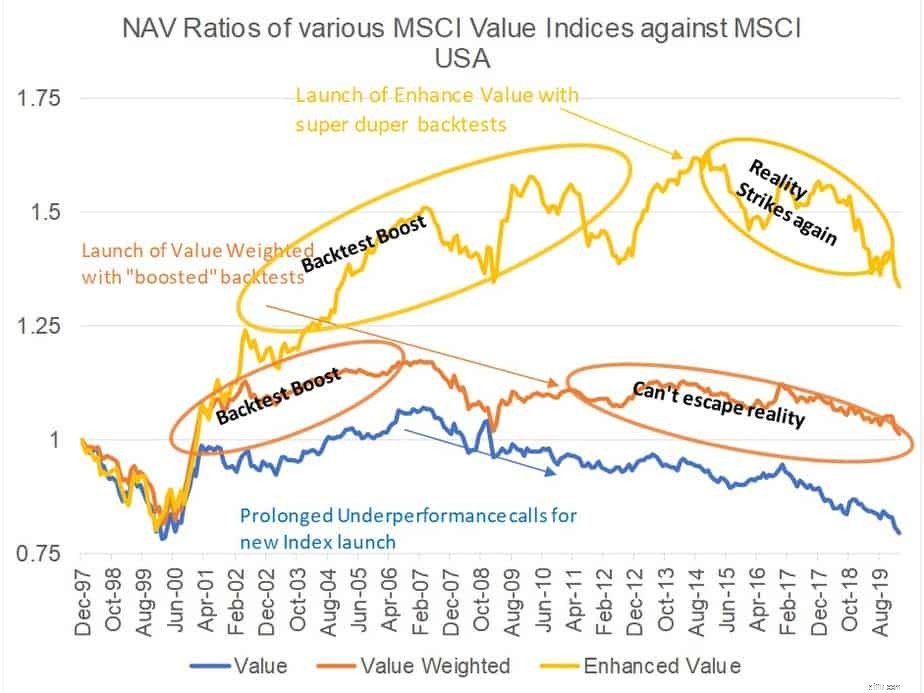
데이터 마이닝이 있다고 어떻게 확신하는지 궁금할 수 있습니다. 왜 우리는 그들에게 의심의 이익을 줄 수 없습니까? 글쎄, 그것은 그들의 방법론 문서에 공개되어 있습니다. 다음은 MSCI가 요인을 구성할 때 여러 변수와 가중치를 선택하는 방법을 발췌한 것입니다. 그들은 백테스트에서 더 나은 수익률/변동성을 보인 변수를 과대평가했음을 노골적으로 인정합니다. 이것이 데이터 마이닝의 교과서적인 정의이며 공개적으로 데이터 마이닝을 한다고 말합니다. 그것은 두 가지 중 하나만 의미할 수 있습니다. 1. 그들은 데이터 마이닝을 하는지조차 모릅니다. 2. 그들은 단순히 신경 쓰지 않습니다. 두 가지 이유 중 어느 것이 다른 것보다 더 위험한지 모르겠습니다.
이것은 MSCI FaCS 방법론 문서 8페이지의 스크린샷입니다.
<노스크립트>
텍스트는 명확성을 위해 아래에 재현되어 있습니다.
독자들은 이것이 미국 데이터, 미국 지수, 미국 제공자인지 물을 것입니다. 저는 단순히 인도의 뮤추얼 펀드에 투자하고 있습니다. 왜 내가 관심을 가져야 합니까? 문제가 백 테스트 트랙 레코드, 건설 방법론, 출시 날짜 및 라이브 트랙 레코드가 공개된 지수에서 노골적으로 만연한 경우, 아무 것도 액세스할 수 없는 좋아하는 활성 펀드의 규모와 규모를 상상해 보십시오. 투명도가 0입니다. 인덱스는 규칙에 기반하고 체계적이지만 액티브 뮤추얼 펀드는 전적으로 재량입니다. 뮤추얼 펀드 산업에서 데이터 마이닝이 만연하게 될 규모를 짐작할 수 없습니다. 고맙게도 SEBI는 각 범주의 자금 수를 제한하는 규칙을 마련했습니다.
이것은 우리가 어떤 것도 백 테스트하거나 백 테스트 성능을 절대 보지 않는다는 것을 말하는 것이 아닙니다. 당연히 아니지. 과거 데이터는 결정을 내리는 데 사용할 수 있는 유일한 정보입니다. 소금 한 꼬집과 함께 섭취해야 합니다. Pattu Sir이 말했듯이 "최고의 과거 수익을 따는 것은 잘못된 것입니다. 체리 따기 최악의 과거 위험은 신중함입니다." 그 정도입니다. 데이터 마이닝이 무엇이고 무엇이 아닌지에 대한 한 줄 요약입니다. 이것이 투자자로서 위험을 이해하기 위해 백테스트 또는 과거 데이터를 일반적으로 취급하는 방식입니다. 업계는 희망이 없습니다.